
The Beautiful Voice
The 2026 Hackathon Project update of my attempt to use AI to build an MLB Game broadcast

In 2025 we had the idea to run a hackathon at the office through the month of mAI with a specific focus on AI. At the time, it was really starting to appear everywhere, in everything. It still is today but it used to be too. We wanted people to experiment and see what they could come up with. A month is a long time for a hackathon, but for someone like me who celebrates the birthdays of two daughters, Mother’s Day, my own birthday, and the start of Summer activities for the kiddos while the Winter and Spring activities are not quite finishing up, a month allows for folks to be able to put something together on their own time, and ultimately that was the goal of the hackathon. It wasn’t about having a polished product, it wasn’t about securing millions in funding, it wasn’t about “finishing your shit”, it was about learning, and it was about fun, and it was about exploring the art of the possible as the industry changes around us.
I went with my normal default and focussed on an idea around sports, specifically baseball. I had seen a tweet showing off the capabilities of an open source text to speech model called Dia that was quite impressive and decided that what I wanted to do was build what was essentially a radio broadcast that I could generate with the help of OpenAI APIs and Dia by consuming the data feeds that power the MLB game day apps (the GUMBO API). I’ve played with these data feeds a lot so I was familiar enough with them that I knew that it was something that I should be able to accomplish.
Overall, I’d call the project a success. It wasn’t perfect, but I learned a ton and more importantly I had more fun building that than I had had in years building something. That said, this was very much a hackathon project as you’d build it in 2025. Vibe coding had arrived, but it was built to prove I could do it. The result is below…
The 2025 version worked, but it was definitely a hackathon project… in that it was a mess. It was basically two scripts doing everything: a Node file (game.js) that walked the game feed, built the prompt, and called the LLM all in one breath, and a Python server.py that did the voice synthesis and the streaming. I ran both files on a RunPod instance (GPU goes brrrr), but it was always an adventure, and that instance was not cheap to run, so I was constantly start/stopping it, and if I forgot that “stop”, I was being sent messages that I needed to re-up my balance.
The big thing that I needed to fix was the lack of storytelling/continuity in what was being generated by my project. Every new piece of script kept repeating the different game elements that didn’t need to be repeated — the inning, the number of outs. Those are important details, but they need to be sprinkled in; they don’t need to be repeated every time the colour commentator or the play-by-play announcer speaks, and I wanted to be able to fine-tune the OpenAI API that I was using to generate the script by seeding it with some real transcripts from actual baseball games. Because I’m me, I can never settle for the bare minimum — especially not now, with how powerful these agents have proven to be and how they can allow me to maximize the use of my time.
The 2026 rebuild was aided heavily by AI. I spent about 30 minutes putting a plan together in Claude, which was mostly about prioritizing the goals and figuring out how we could break things apart in a way that was practical and sensible. Single responsibility, you can still do proper “engineering” even when you are vibing. Once everything had a clear job, the whole thing got way easier to reason about, test, demo, and what ended up being most important, adjust and really stretch what I was trying to do as it was building. We also wanted to re-use what already existed, where it would make sense.
NodeJS
In 2025, the Node script figured out what to say. The rebuild took this to the next level, adding additional context, emotion, and maybe most importantly, what NOT to say… One play object (EnrichedPlay) flows through a chain of small modules, each one adding something:
- GameTicker — the clock. Walks the game timestamp by timestamp and hands each play down the line. (In 2025 this was just an inline loop; now it’s its own thing with a speed knob for fast replay, and it will handle games in real time as the feed is updated.)
- GameStateService — turns the raw GUMBO into a normalized play shape, and tags the delta from the last play. It’s this normalized object that acts as our source of truth through the rest of the process.
- Narrative Thread Engine — the memory for storylines. Tracks the ongoing threads a real announcer would (“this pitcher’s dealing,” “late and close”) as 12 little predicates over the last 30 plays. Each predicate is just a small yes/no rule — “has this pitcher struck out 4 of the last 6?”, “does this batter already have two hits tonight?” — and the engine keeps a rolling window of the 30 most recent plays for them to look back over. On every new play it re-runs each and collects whichever ones fire; a storyline naturally goes stale once the plays behind it age out of the window.
- HighlightDetector — decides how big a moment a play is (routine → holy_shit, and a number of steps in between) with plain rules. This is not determined with AI as there were a number of issues during development. Also responsible for setting the energy of the broadcasters.
- ScriptGenerator — pulls all of the above into a prompt and produces the two-voice
[S1]/[S2]script. This is the only part that talks to the LLM. The script format was a leftover from the Dia implementation in 2025. More on that to come, but one question I have for next year is if things could be improved by splitting this up.
The key difference here: in the old version all five of those jobs lived in one function. Now they’re a pipeline, and each piece is unit-tested on its own and is much simpler to extend and/or debug.
Python (can’t believe I didn’t end up referring to this piece as “earworm”, but I digress…)
Python takes the finished script and turns it into the live audio stream. Node POSTs the text over; Python handles the rest:
- TTSService — A couple of weeks into the month, I ended up loading up some credits in ElevenLabs for an event we were having at the office. I was blown away by the quality of what I heard. I would come home at night and work on this, but my version was consistently lacking. This service splits the script by speaker, sends each line to the right voice (I had a lot of fun creating one of the voices here…), and drops the audio into a queue.
- HLS Segmenter — A background loop chops the generated WAVs into 2-second chunks with ffmpeg and keeps a rolling playlist going, filling gaps with silence so the stream never stalls. I tried to figure out how to add generic crowd noise as background (note: SCOPE CREEP) but was unable to get anywhere with that.
- Player (browser) — Python is a bit of a stretch here… this was a simple webserver that plays the HLS stream.
In 2025 I had the most basic website I could, an h1 tag and an audio element that would stream the HLS audio. I had a lot of fun leveraging Claude Design, which I had been looking for an excuse to play with and I was very happy with the result, and had a lot of fun hooking up additional elements, like the live scoreboard, count, and base diamond, kept (mostly) in sync with the audio over a separate state channel. This was definitely something that I probably should have focused on a bit less, but I am a sucker for nice looking websites, and this was a VERY nice looking website…
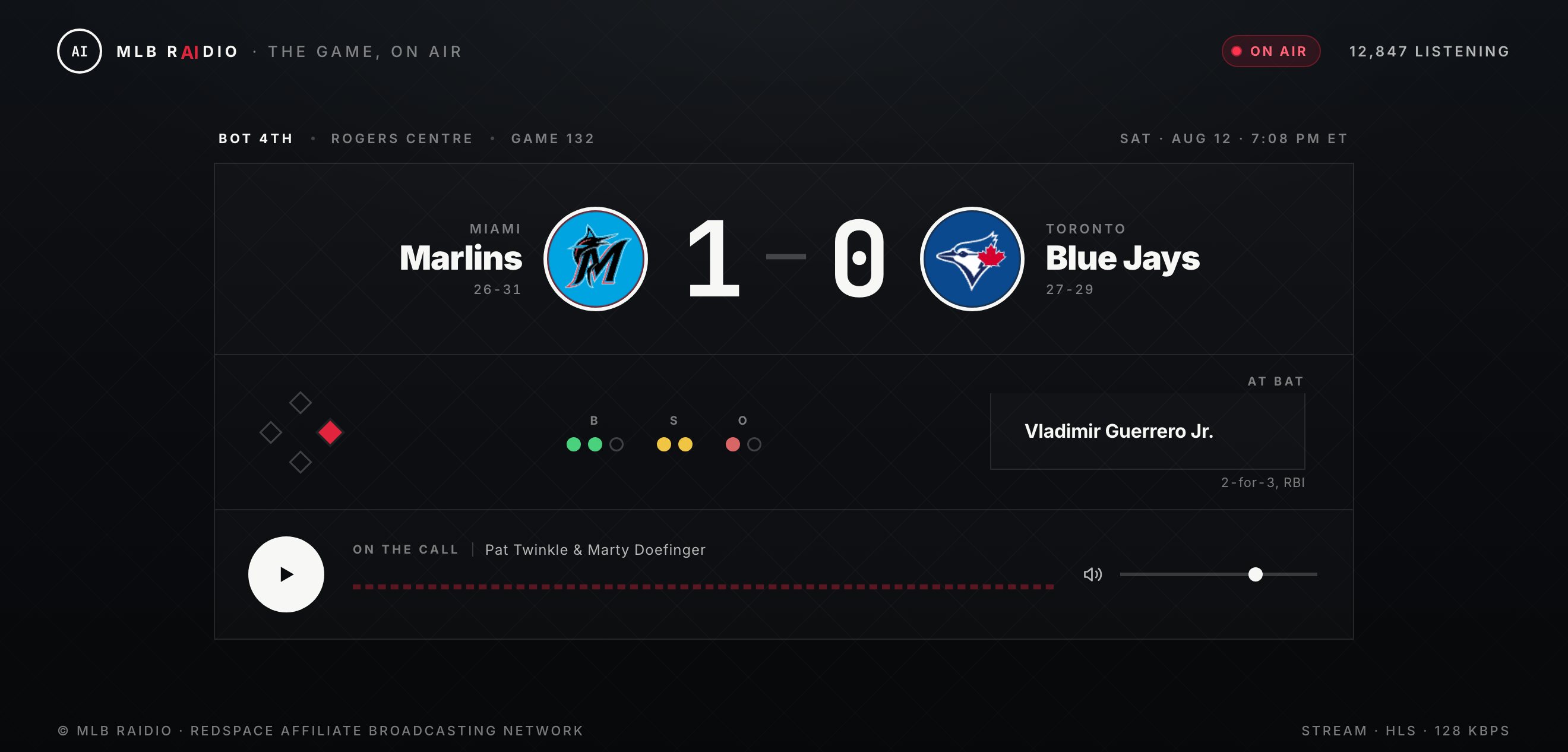
In 2025 the Python side was one tangled file with the voice model hard-wired in. Now it’s one clean server with the voice engine behind a switch, and the streaming hardened against all the live-HLS footguns we hit along the way.
Why it worked so well
The reason it all came together is that split. Node never has to care how audio gets made; Python never has to care how the script got written. The handoff is just one HTTP POST of plain text. That meant I could swap the voice engine (Dia → ElevenLabs) without touching the brain, tune the broadcast’s personality without touching the audio plumbing, and test every piece in isolation. The 2025 version couldn’t do any of that.
The Result
Was it worth it? I’ll let you be the judge…
Watching the two side by side is really the whole story. The 2025 version proved I could do it. The 2026 version is a clear improvement. I am happy, but I am not satisfied… There’s still a lot that can be done.
What was really eye-opening was how much further the tooling let me push in the same number of nights. 2025 was me proving a point to myself. 2026 was perhaps going too far… there’s a good lesson about why we need constraints and how that inevitably benefits us… Based on how much time I spent working on things I didn’t really need, nice as they may be, I really feel like I could have improved the overall project by spending less time worrying about what I COULD do and more on what I SHOULD do.
Obviously there are bugs to be worked out, things that can be improved still, and obviously there will be more products, more features, more tools that can be integrated and really take the art of the possible in this project to the next level. I’m forever busy, but I hope that it doesn’t take the full year to get back to it.